
Quick Links
Key Takeaways
- awk is used to filter and manipulate output from other programs by applying rules with patterns and actions.
- awk can print specific fields from text, modify separators between fields, and perform various actions using built-in functions.
- awk is named after its creators: Alfred Aho, Peter Weinberger, and Brian Kernighan.
On Linux, awk is a command-line text manipulation dynamo, as well as a powerful scripting language. Here's an introduction to some of its coolest features.
How awk Got Its Name
The awk command was named using the initials of the three people who wrote the original version in 1977: Alfred Aho, Peter Weinberger, and Brian Kernighan. These three men were from the legendary AT&T Bell Laboratories Unix pantheon. With the contributions of many others since then, awk has continued to evolve.
It's a full scripting language, as well as a complete text manipulation toolkit for the command line. If this article whets your appetite, you can check out every detail about awk and its functionality.
What is awk Used For? Rules, Patterns, and Actions
awk is used to filter and manipulate output from other programs and functions. awk works on programs that contain rules comprised of patterns and actions. The action awk takes is executed on the text that matches the pattern. Patterns are enclosed in curly braces ({}). Together, a pattern and an action form a rule. The entire awk program is enclosed in single quotes (').
Let's take a look at the simplest type of awk program. It has no pattern, so it matches every line of text fed into it. This means the action is executed on every line. We'll use it on the output from the who command.
Here's the standard output from who:
who
Perhaps we don't need all of that information, but, rather, just want to see the names on the accounts. We can pipe the output from who into awk, and then tell awk to print only the first field.
By default, awk considers a field to be a string of characters surrounded by whitespace, the start of a line, or the end of a line. Fields are identified by a dollar sign ($) and a number. So, $1 represents the first field, which we'll use with the print action to print the first field.
We type the following:
who | awk '{print $1}'
awk prints the first field and discards the rest of the line.
We can print as many fields as we like. If we add a comma as a separator, awk prints a space between each field.
We type the following to also print the time the person logged in (field four):
who | awk '{print $1,$4}'
There are a couple of special field identifiers. These represent the entire line of text and the last field in the line of text:
- $0: Represents the entire line of text.
- $1: Represents the first field.
- $2: Represents the second field.
- $7: Represents the seventh field.
- $45: Represents the 45th field.
- $NF: Stands for "number of fields," and represents the last field.
We'll type the following to bring up a small text file that contains a short quote attributed to Dennis Ritchie:
cat dennis_ritchie.txt
We want awk to print the first, second, and last field of the quote. Note that although it's wrapped around in the terminal window, it's just a single line of text.
We type the following command:
awk '{print $1,$2,$NF}' dennis_ritchie.txt
We don't know that "simplicity." is the 18th field in the line of text, and we don't care. What we do know is it's the last field, and we can use $NF to get its value. The period is just considered another character in the body of the field.
Adding Output Field Separators to awk Output
You can also tell awk to print a particular character between fields instead of the default space character. The default output from the date command is slightly peculiar because the time is plonked right in the middle of it. However, we can type the following and use awk to extract the fields we want:
date
date | awk '{print $2,$3,$6}'
We'll use the OFS (output field separator) variable to put a separator between the month, day, and year. Note that below we enclose the command in single quotes ('), not curly braces ({}):
date | awk 'OFS="/" {print$2,$3,$6}'
date | awk 'OFS="-" {print$2,$3,$6}'
The BEGIN and END Rules
A BEGIN rule is executed once before any text processing starts. In fact, it's executed before awk even reads any text. An END rule is executed after all processing has completed. You can have multiple BEGIN and END rules, and they'll execute in order.
For our example of a BEGIN rule, we'll print the entire quote from the dennis_ritchie.txt file we used previously with a title above it.
To do so, we type this command:
awk 'BEGIN {print "Dennis Ritchie"} {print $0}' dennis_ritchie.txt
Note the BEGIN rule has its own set of actions enclosed within its own set of curly braces ({}).
We can use this same technique with the command we used previously to pipe output from who into awk. To do so, we type the following:
who | awk 'BEGIN {print "Active Sessions"} {print $1,$4}'
Input Field Separators
If you want awk to work with text that doesn't use whitespace to separate fields, you have to tell it which character the text uses as the field separator. For example, the /etc/passwd file uses a colon (:) to separate fields.
We'll use that file and the -F (separator string) option to tell awk to use the colon (:) as the separator. We type the following to tell awk to print the name of the user account and the home folder:
awk -F: '{print $1,$6}' /etc/passwd
The output contains the name of the user account (or application or daemon name) and the home folder (or the location of the application).
Adding Patterns to awk
If all we're interested in are regular user accounts, we can include a pattern with our print action to filter out all other entries. Because User ID numbers are equal to, or greater than, 1,000, we can base our filter on that information.
We type the following to execute our print action only when the third field ($3) contains a value of 1,000 or greater:
awk -F: '$3 >= 1000 {print $1,$6}' /etc/passwd
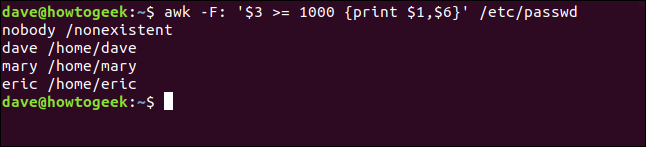
The pattern should immediately precede the action with which it's associated.
We can use the BEGIN rule to provide a title for our little report. We type the following, using the (\n) notation to insert a newline character into the title string:
awk -F: 'BEGIN {print "User Accounts\n-------------"} $3 >= 1000 {print $1,$6}' /etc/passwd
Patterns are full-fledged regular expressions, and they're one of the glories of awk.
Let's say we want to see the universally unique identifiers (UUIDs) of the mounted file systems. If we search through the /etc/fstab file for occurrences of the string "UUID," it ought to return that information for us.
We use the search pattern "/UUID/" in our command:
awk '/UUID/ {print $0}' /etc/fstab
It finds all occurrences of "UUID" and prints those lines. We actually would've gotten the same result without the print action because the default action prints the entire line of text. For clarity, though, it's often useful to be explicit. When you look through a script or your history file, you'll be glad you left clues for yourself.
The first line found was a comment line, and although the "UUID" string is in the middle of it, awk still found it. We can tweak the regular expression and tell awk to process only lines that start with "UUID." To do so, we type the following which includes the start of line token (^):
awk '/^UUID/ {print $0}' /etc/fstab
That's better! Now, we only see genuine mount instructions. To refine the output even further, we type the following and restrict the display to the first field:
awk '/^UUID/ {print $1}' /etc/fstab
If we had multiple file systems mounted on this machine, we'd get a neat table of their UUIDs.
How to Use awk's Built-In Functions
awk has many functions you can call and use in your own programs, both from the command line and in scripts. If you do some digging, you'll find it very fruitful.
To demonstrate the general technique to call a function, we'll look at some numeric ones. For example, the following prints the square root of 625:
awk 'BEGIN { print sqrt(625)}'
This command prints the arctangent of 0 (zero) and -1 (which happens to be the mathematical constant, pi):
awk 'BEGIN {print atan2(0, -1)}'
In the following command, we modify the result of the atan2() function before we print it:
awk 'BEGIN {print atan2(0, -1)*100}'
Functions can accept expressions as parameters. For example, here's a convoluted way to ask for the square root of 25:
awk 'BEGIN { print sqrt((2+3)*5)}'
awk Scripts
If your command line gets complicated, or you develop a routine you know you'll want to use again, you can transfer your awk command into a script.
In our example script, we're going to do all of the following:
- Tell the shell which executable to use to run the script.
- Prepare
awkto use theFSfield separator variable to read input text with fields separated by colons (:). - Use the
OFSoutput field separator to tellawkto use colons (:) to separate fields in the output. - Set a counter to 0 (zero).
- Set the second field of each line of text to a blank value (it's always an "x," so we don't need to see it).
- Print the line with the modified second field.
- Increment the counter.
- Print the value of the counter.
Our script is shown below.
The BEGIN rule carries out the preparatory steps, while the END rule displays the counter value. The middle rule (which has no name, nor pattern so it matches every line) modifies the second field, prints the line, and increments the counter.
The first line of the script tells the shell which executable to use (awk, in our example) to run the script. It also passes the -f (filename) option to awk, which informs it the text it's going to process will come from a file. We'll pass the filename to the script when we run it.
We've included the script below as text so you can cut and paste:
#!/usr/bin/awk -fBEGIN { # set the input and output field separators FS=":" OFS=":" # zero the accounts counter accounts=0}{ # set field 2 to nothing $2="" # print the entire line print $0 # count another account accounts++}END { # print the results print accounts " accounts.\n"}
Save this in a file called omit.awk. To make the script executable, we type the following using chmod:
chmod +x omit.awk
Now, we'll run it and pass the /etc/passwd file to the script. This is the file awk will process for us, using the rules within the script:
./omit.awk /etc/passwd
The file is processed and each line is displayed, as shown below.
The "x" entries in the second field were removed, but note the field separators are still present. The lines are counted and the total is given at the bottom of the output.
awk Doesn't Stand for Awkward
awk doesn't stand for awkward; it stands for elegance. It's been described as a processing filter and a report writer. More accurately, it's both of these, or, rather, a tool you can use for both of these tasks. In just a few lines, awk achieves what requires extensive coding in a traditional language.
That power is harnessed by the simple concept of rules that contain patterns, that select the text to process, and actions that define the processing.