
Quick Links
Key Takeaways
- The Linux sed command is a powerful text editor without an interface, used for manipulating text in files and streams.
- Sed can select, substitute, add, delete, and modify text in files and streams, providing instructions for it to follow as it works.
- Sed relies heavily on regular expressions for pattern matching and text selection, and familiarity with regexes is important for using sed effectively.
It might sound crazy, but the Linux sed command is a text editor without an interface. You can use it from the command line to manipulate text in files and streams. We'll show you how to harness its power.
The Power of sed
The sed command is a bit like chess: it takes an hour to learn the basics and a lifetime to master them (or, at least a lot of practice). We'll show you a selection of opening gambits in each of the main categories of sed functionality.
sed is a stream editor that works on piped input or files of text. It doesn't have an interactive text editor interface, however. Rather, you provide instructions for it to follow as it works through the text. This all works in Bash and other command-line shells.
With sed you can do all of the following:
- Select text
- Substitute text
- Add lines to text
- Delete lines from text
- Modify (or preserve) an original file
We've structured our examples to introduce and demonstrate concepts, not to produce the tersest (and least approachable) sed commands. However, the pattern matching and text selection functionalities of sed rely heavily on regular expressions (regexes). You're going to need some familiarity with these to get the best out of sed.
A Simple Example
First, we're going to use echo to send some text to sed through a pipe, and have sed substitute a portion of the text. To do so, we type the following:
echo howtogonk | sed 's/gonk/geek/'
The echo command sends "howtogonk" into sed, and our simple substitution rule (the "s" stands for substitution) is applied. sed searches the input text for an occurrence of the first string, and will replace any matches with the second.
The string "gonk" is replaced by "geek," and the new string is printed in the terminal window.
Substitutions are probably the most common use of sed. Before we can dive deeper into substitutions, though, we need to know how to select and match text.
Selecting Text
We're going to need a text file for our examples. We'll use one that contains a selection of verses from Samuel Taylor Coleridge's epic poem "The Rime of the Ancient Mariner."
We type the following to take a look at it with less:
less coleridge.txt
To select some lines from the file, we provide the start and end lines of the range we want to select. A single number selects that one line.
To extract lines one to four, we type this command:
sed -n '1,4p' coleridge.txt
Note the comma between 1 and 4. The p means "print matched lines." By default, sed prints all lines. We'd see all the text in the file with the matching lines printed twice. To prevent this, we'll use the -n (quiet) option to suppress the unmatched text.
We change the line numbers so we can select a different verse, as shown below:
sed -n '6,9p' coleridge.txt
We can use the -e (expression) option to make multiple selections. With two expressions, we can select two verses, like so:
sed -n -e '1,4p' -e '31,34p' coleridge.txt
If we reduce the first number in the second expression, we can insert a blank between the two verses. We type the following:
sed -n -e '1,4p' -e '30,34p' coleridge.txt
We can also choose a starting line and tell sed to step through the file and print alternate lines, every fifth line, or to skip any number of lines. The command is similar to those we used above to select a range. This time, however, we'll use a tilde (~) instead of a comma to separate the numbers.
The first number indicates the starting line. The second number tells sed which lines after the starting line we want to see. The number 2 means every second line, 3 means every third line, and so on.
We type the following:
sed -n '1~2p' coleridge.txt
You won't always know where the text you're looking for is located in the file, which means line numbers won't always be much help. However, you can also use sed to select lines that contain matching text patterns. For example, let's extract all lines that start with "And."
The caret (^) represents the start of the line. We'll enclose our search term in forward slashes (/). We also include a space after "And" so words like "Android" won't be included in the result.
Reading sed scripts can be a bit tough at first. The /p means "print," just as it did in the commands we used above. In the following command, though, a forward slash precedes it:
sed -n '/^And /p' coleridge.txt
Three lines that start with "And " are extracted from the file and displayed for us.
Making Substitutions
In our first example, we showed you the following basic format for a sed substitution:
echo howtogonk | sed 's/gonk/geek/'
The s tells sed this is a substitution. The first string is the search pattern, and the second is the text with which we want to replace that matched text. Of course, as with all things Linux, the devil is in the details.
We type the following to change all occurrences of "day" to "week," and give the mariner and albatross more time to bond:
sed -n 's/day/week/p' coleridge.txt
In the first line, only the second occurrence of "day" is changed. This is because sed stops after the first match per line. We have to add a "g" at the end of the expression, as shown below, to perform a global search so all matches in each line are processed:
sed -n 's/day/week/gp' coleridge.txt
This matches three out of the four in the first line. Because the first word is "Day," and sed is case-sensitive, it doesn't consider that instance to be the same as "day."
We type the following, adding an i to the command at the end of the expression to indicate case-insensitivity:
sed -n 's/day/week/gip' coleridge.txt
This works, but you might not always want to turn on case-insensitivity for everything. In those instances, you can use a regex group to add pattern-specific case-insensitivity.
For example, if we enclose characters in square brackets ([]), they're interpreted as "any character from this list of characters."
We type the following, and include "D" and "d" in the group, to ensure it matches both "Day" and "day":
sed -n 's/[Dd]ay/week/gp' coleridge.txt
We can also restrict substitutions to sections of the file. Let's say our file contains weird spacing in the first verse. We can use the following familiar command to see the first verse:
sed -n '1,4p' coleridge.txt
We'll search for two spaces and substitute them with one. We'll do this globally so the action is repeated across the entire line. To be clear, the search pattern is space, space asterisk (*), and the substitution string is a single space. The 1,4 restricts the substitution to the first four lines of the file.
We put all of that together in the following command:
sed -n '1,4 s/ */ /gp' coleridge.txt
This works nicely! The search pattern is what's important here. The asterisk (*) represents zero or more of the preceding character, which is a space. Thus, the search pattern is looking for strings of one space or more.
If we substitute a single space for any sequence of multiple spaces, we'll return the file to regular spacing, with a single space between each word. This will also substitute a single space for a single space in some cases, but this won't affect anything adversely---we'll still get our desired result.
If we type the following and reduce the search pattern to a single space, you'll see immediately why we have to include two spaces:
sed -n '1,4 s/ */ /gp' coleridge.txt
Because the asterisk matches zero or more of the preceding character, it sees each character that isn't a space as a "zero space" and applies the substitution to it.
However, if we include two spaces in the search pattern, sed must find at least one space character before it applies the substitution. This ensures nonspace characters will remain untouched.
We type the following, using the -e (expression) we used earlier, which allows us to make two or more substitutions simultaneously:
sed -n -e 's/motion/flutter/gip' -e 's/ocean/gutter/gip' coleridge.txt
We can achieve the same result if we use a semicolon (;) to separate the two expressions, like so:
sed -n 's/motion/flutter/gip;s/ocean/gutter/gip' coleridge.txt
When we swapped "day" for "week" in the following command, the instance of "day" in the expression "well a-day" was swapped as well:
sed -n 's/[Dd]ay/week/gp' coleridge.txt
To prevent this, we can only attempt substitutions on lines that match another pattern. If we modify the command to have a search pattern at the start, we'll only consider operating on lines that match that pattern.
We type the following to make our matching pattern the word "after":
sed -n '/after/ s/[Dd]ay/week/gp' coleridge.txt
That gives us the response we want.
More Complex Substitutions
Let's give Coleridge a break and use sed to extract names from the etc/passwd file.
There are shorter ways to do this (more on that later), but we'll use the longer way here to demonstrate another concept. Each matched item in a search pattern (called subexpressions) can be numbered (up to a maximum of nine items). You can then use these numbers in your sed commands to reference specific subexpressions.
You have to enclose the subexpression in parentheses [()] for this to work. The parentheses also must be preceded by a backward slash (\) to prevent them from being treated as a normal character.
To do this, you would type the following:
sed 's/\([^:]*\).*/\1/' /etc/passwd
Let's break this down:
-
sed 's/: Thesedcommand and the beginning of the substitution expression. -
\(: The opening parenthesis [(] enclosing the subexpression, preceded by a backslash (\). -
[^:]*: The first subexpression of the search term contains a group in square brackets. The caret (^) means "not" when used in a group. A group means any character that isn't a colon (:) will be accepted as a match. -
\): The closing parenthesis [)] with a preceding backslash (\). -
.*: This second search subexpression means "any character and any number of them." -
/\1: The substitution portion of the expression contains1preceded by a backslash (\). This represents the text that matches the first subexpression. -
/': The closing forward-slash (/) and single quote (') terminate thesedcommand.
What this all means is we're going to look for any string of characters that doesn't contain a colon (:), which will be the first instance of matching text. Then, we're searching for anything else on that line, which will be the second instance of matching text. We're going to substitute the entire line with the text that matched the first subexpression.
Each line in the /etc/passwd file starts with a colon-terminated username. We match everything up to the first colon, and then substitute that value for the entire line. So, we've isolated the usernames.
Next, we'll enclose the second subexpression in parentheses [()] so we can reference it by number, as well. We'll also replace \1 with \2. Our command will now substitute the entire line with everything from the first colon (:) to the end of the line.
We type the following:
sed 's/\([^:]*\)\(.*\)/\2/' /etc/passwd
Those small changes invert the meaning of the command, and we get everything except the usernames.
Now, let's take a look at the quick and easy way to do this.
Our search term is from the first colon (:) to the end of the line. Because our substitution expression is empty (//), we won't replace the matched text with anything.
So, we type the following, chopping off everything from the first colon (:) to the end of the line, leaving just the usernames:
sed 's/:.*//" /etc/passwd
Let's look at an example in which we reference the first and second matches in the same command.
We've got a file of commas (,) separating first and last names. We want to list them as "last name, first name." We can use cat, as shown below, to see what's in the file:
cat geeks.txt
Like a lot of sed commands, this next one might look impenetrable at first:
sed 's/^\(.*\),\(.*\)$/\2,\1 /g' geeks.txt
This is a substitution command like the others we've used, and the search pattern is quite easy. We'll break it down below:
-
sed 's/: The normal substitution command. -
^: Because the caret isn't in a group ([]), it means "The start of the line." -
\(.*\),: The first subexpression is any number of any characters. It's enclosed in parentheses [()], each of which is preceded by a backslash (\) so we can reference it by number. Our entire search pattern so far translates as search from the start of the line up to the first comma (,) for any number of any characters. -
\(.*\): The next subexpression is (again) any number of any character. It's also enclosed in parentheses [()], both of which are preceded by a backslash (\) so we can reference the matching text by number. -
$/: The dollar sign ($) represents the end of the line and will allow our search to continue to the end of the line. We've used this simply to introduce the dollar sign. We don't really need it here, as the asterisk (*) would go to the end of the line in this scenario. The forward slash (/) completes the search pattern section. -
\2,\1 /g': Because we enclosed our two subexpressions in parentheses, we can refer to both of them by their numbers. Because we want to reverse the order, we type them assecond-match,first-match. The numbers have to be preceded by a backslash (\). -
/g: This enables our command to work globally on each line. -
geeks.txt: The file we're working on.
You can also use the Cut command (c) to substitute entire lines that match your search pattern. We type the following to search for a line with the word "neck" in it, and replace it with a new string of text:
sed '/neck/c Around my wrist was strung' coleridge.txt
Our new line now appears at the bottom of our extract.
Inserting Lines and Text
We can also insert new lines and text into our file. To insert new lines after any matching ones, we'll use the Append command (a).
Here's the file we're going to work with:
cat geeks.txt
We've numbered the lines to make this a bit easier to follow.
We type the following to search for lines that contain the word "He," and insert a new line beneath them:
sed '/He/a --> Inserted!' geeks.txt

We type the following and include the Insert Command (i) to insert the new line above those that contain matching text:
sed '/He/i --> Inserted!' geeks.txt
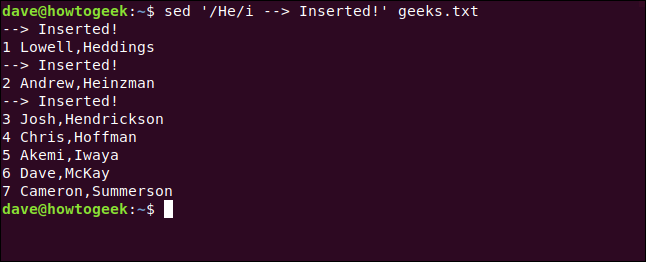
We can use the ampersand (&), which represents the original matched text, to add new text to a matching line. \1 , \2, and so on, represent matching subexpressions.
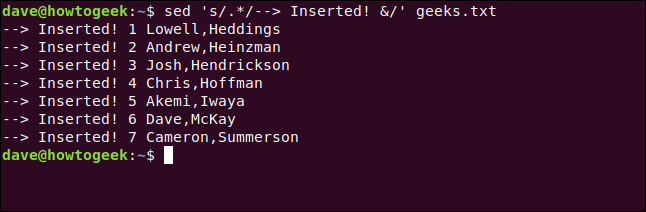
To add text to the start of a line, we'll use a substitution command that matches everything on the line, combined with a replacement clause that combines our new text with the original line.
To do all of this, we type the following:
sed 's/.*/--> Inserted &/' geeks.txt
We type the following, including the G command, which will add a blank line between each line:
sed 'G' geeks.txt
If you want to add two or more blank lines, you can use G;G, G;G;G, and so on.
Deleting Lines
The Delete command (d) deletes lines that match a search pattern, or those specified with line numbers or ranges.
For example, to delete the third line, we would type the following:
sed '3d' geeks.txt
To delete the range of lines four to five, we'd type the following:
sed '4,5d' geeks.txt
To delete lines outside a range, we use an exclamation point (!), as shown below:
sed '6,7!d' geeks.txt
Saving Your Changes
So far, all of our results have printed to the terminal window, but we haven't yet saved them anywhere. To make these permanent, you can either write your changes to the original file or redirect them to a new one.
Overwriting your original file requires some caution. If your sed command is wrong, you might make some changes to the original file that are difficult to undo.
For some peace of mind, sed can create a backup of the original file before it executes its command.
You can use the In-place option (-i) to tell sed to write the changes to the original file, but if you add a file extension to it, sed will back up the original file to a new one. It will have the same name as the original file, but with a new file extension.
To demonstrate, we'll search for any lines that contain the word "He" and delete them. We'll also back up our original file to a new one using the BAK extension.
To do all of this, we type the following:
sed -i'.bak' '/^.*He.*$/d' geeks.txt
We type the following to make sure our backup file is unchanged:
cat geeks.txt.bak
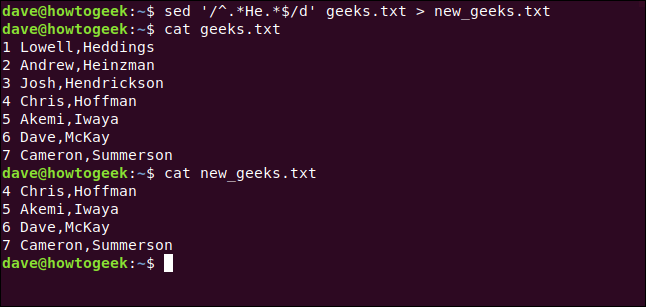
We can also type the following to redirect the output to a new file and achieve a similar result:
sed -i'.bak' '/^.*He.*$/d' geeks.txt > new_geeks.txt
We use cat to confirm the changes were written to the new file, as shown below:
cat new_geeks.txt
Having sed All That
As you've probably noticed, even this quick primer on sed is quite long. There's a lot to this command, and there's even more you can do with it.
Hopefully, though, these basic concepts have provided a solid foundation on which you can build as you continue to learn more.